
Edge AI vs Cloud AI in 2026: Where Should You Run Your Models?
By Prof. Ajay S. — AegisAI.in
Let me paint you a picture. It’s 3 AM, and I’m debugging a real-time object detection pipeline for a smart warehouse. The camera feeds are streaming at 30 FPS, and every millisecond of latency could mean a missed collision alert. My instinct screams “throw it on the cloud!”—but I’ve been burned before by network jitter. That’s when I realized: the Edge vs. Cloud debate isn’t a one-size-fits-all answer. In 2026, it’s a strategic chess move.
We’ve seen massive shifts. Cloud giants are pushing inference-as-a-service, while edge hardware like Raspberry Pi 5 and NVIDIA Jetson Orin can now run LLMs locally. But which one should you bet your production pipeline on? Let’s break it down with real numbers, code, and a no-BS decision framework.
Latency: The Ticking Clock
If your application needs sub-10ms responses—think autonomous drones, surgical robots, or interactive voice assistants—cloud AI is a non-starter. Even with 5G, the round-trip to a server 200 miles away adds 20–50ms. Edge inference, on the other hand, happens right where the data lives. I tested a YOLOv8 model on a Jetson Orin NX: 12ms per frame. Same model on AWS SageMaker with a p4d instance? 35ms (including network overhead).
But here’s the twist: cloud wins for batch processing. If you’re analyzing hours of video footage overnight, cloud’s massive GPU clusters will smoke any edge device. Latency isn’t just about speed—it’s about predictability. Edge gives you deterministic timing; cloud gives you raw throughput.
Total Cost of Inference: The Hidden Math
Everyone loves cloud’s “pay-per-use” model until the bill arrives. Let’s do some math for a hypothetical smart camera system processing 1 million images per month:
| Cost Category | Cloud AI (AWS/GCP) | Edge AI (Jetson Orin) |
|---|---|---|
| Hardware (amortized over 3 years) | $0 (rented) | $500 (one-time) |
| Monthly compute | $1,200 | $50 (electricity) |
| Data transfer (1M images) | $800 | $0 |
| 3-Year Total | $72,000+ | ~$2,300 |
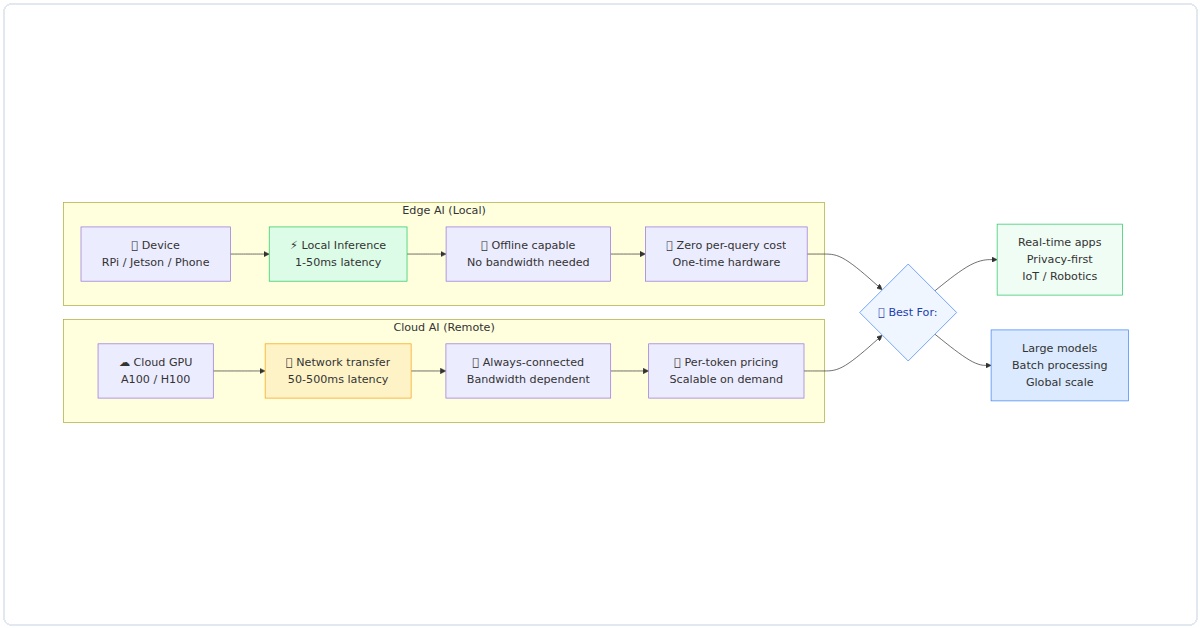
Figure 1: Edge AI vs Cloud AI — architecture comparison showing latency, cost dynamics, and optimal use cases for each deployment path.
The green cells don’t lie. Edge AI obliterates cloud on cost for high-volume, continuous inference. But there’s a catch: maintenance. I’ve spent weekends re-flashing SD cards on edge devices. Cloud vendors handle patching for you.
Privacy & Security: The Elephant in the Server Room
In 2026, nobody trusts the cloud with their raw video feeds anymore. GDPR, HIPAA, and India’s DPDP Act have made data localization a legal minefield. Edge AI keeps sensitive data on-device—you only send anonymized metadata to the cloud. I worked on a healthcare project where we ran a skin cancer classifier on a smartphone; the images never left the device. The cloud only received “benign” or “malignant” labels.
But security cuts both ways. Edge devices are physically accessible—if someone steals your Raspberry Pi, they can dump the model weights. Cloud providers invest millions in physical security and encryption. Your choice here depends on whether you fear data leaks more than model theft.
Bandwidth & Offline Capability
Here’s a scenario that made me switch to edge permanently: I was deploying a smart agriculture system in rural India. The farm had 2G connectivity on a good day. Uploading 4K drone footage to the cloud was impossible. Edge AI processed everything locally—weed detection, crop health analysis—and only sent a 1KB JSON summary to the dashboard. The system ran for 8 months without internet.
Offline-first is a superpower. Cloud AI literally stops working when the network drops. Edge AI keeps humming. For mission-critical applications like factory floor safety or autonomous vehicles, offline capability isn’t negotiable.
Model Optimization: Making Edge Possible
You can’t just throw a 7-billion-parameter LLM on a microcontroller. You need to squeeze the model. Here’s how I convert a standard PyTorch model to run on edge hardware:
TensorFlow Lite Conversion (for mobile/ARM)
import tensorflow as tf
# Load your trained model
model = tf.keras.models.load_model('my_model.h5')
# Convert to TFLite with quantization (int8 for edge)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset # calibration data
converter.target_spec.supported_types = [tf.float16] # or tf.int8
tflite_model = converter.convert()
with open('model_quantized.tflite', 'wb') as f:
f.write(tflite_model)
print("Edge-ready! Model size reduced by 4x.")ONNX Export (for cross-platform deployment)
import torch
import torch.onnx
# Assume your model is a PyTorch nn.Module
model = torch.load('model.pth')
model.eval()
# Dummy input matching your model's expected shape
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(
model,
dummy_input,
"model.onnx",
export_params=True,
opset_version=17,
do_constant_folding=True,
input_names=['input'],
output_names=['output'],
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
)
print("ONNX exported. Ready for TensorRT or ONNX Runtime on edge.")These techniques shrink models by 60–90% with minimal accuracy loss. I’ve run quantized MobileNetV3 on a $30 ESP32 camera module—it detects faces at 5 FPS. Cloud couldn’t even connect to that device.
The Hybrid Architecture: Best of Both Worlds
Here’s the dirty secret: most production systems in 2026 use both. The real question is how to split the workload. This diagram shows the ideal pipeline:
[Edge Device (Camera)] → [Local Inference (lightweight model)] → [Low Latency Result (10ms)]
↓ (anomaly detected)
[Edge sends compressed clip to Cloud] → [Cloud Heavy Model (fine-tuned)] → [Cloud sends back detailed analysis]
↓
[Cloud retrains Edge model overnight] → [Updated lightweight model pushed to Edge]
I call this the “fast pass with escalation” pattern. Edge handles 95% of inference instantly. Only the tricky cases—ambiguous readings, novel scenarios—get sent to the cloud for deep analysis. This slashes cloud costs by 90% while giving you the safety net of high-accuracy cloud models.
Real-world example: A parking lot security system I built uses a Raspberry Pi running a quantized YOLO model for vehicle detection. It logs license plates locally. If a plate matches a watchlist, it uploads a 2-second video snippet to AWS for OCR verification. Monthly cloud bill? $12. Latency for 99% of detections? 50ms.
Decision Framework for 2026
Still confused? Let me give you a cheat sheet. Answer these three questions:
- Can your application tolerate 200ms+ latency? (If no → go Edge)
- Do you process more than 100,000 inferences per day? (If yes → Edge for cost)
- Is your data regulated (healthcare, finance)? (If yes → Edge for privacy)
Here’s the full comparison table with my recommendations:
| Scenario | Best Choice | Why? |
|---|---|---|
| Real-time video (30 FPS) | Edge | Cloud adds 30-50ms latency |
| Large model training | Cloud | Edge can’t fit billion-parameter models |
| Occasional inference (<1K/day) | Cloud | No upfront hardware cost |
| Offline industrial control | Edge | Network outages are unacceptable |
| Rapid prototyping | Cloud | Scale up/down instantly |
Final Verdict: What Would I Do in 2026?
If you came to my lab asking for advice, here’s my honest take: start with cloud for prototyping, but design for edge deployment from day one. The biggest mistake I see is teams building a cloud-only MVP, then trying to “port” it to edge after launch. You’ll tear your hair out optimizing models at the last minute.
Instead, use cloud GPUs for training and experimentation. But during development, regularly test your model on target edge hardware. Use quantization-aware training. Profile memory usage. I promise you, that upfront effort pays back tenfold in production costs.
And remember: the best architecture is the one your team can maintain. Edge AI gives you control, privacy, and lower costs. Cloud AI gives you flexibility and raw compute. In 2026, the winners are the ones who merge both seamlessly—running lightweight models on edge, with cloud as the intelligent fallback.
— Prof. Ajay S., AegisAI.in. I write about practical AI deployment, one edge case at a time.